Solving the
Royal Game of Ur
After 7 years of work, we have finally strongly solved the Royal Game of Ur! That means we can now confidently say that we have found the absolute best move to play from every possible position in the game, under the Finkel, Blitz, and Masters rule sets.
This has allowed us to create a bot, the Panda, that plays the game flawlessly. It has also allowed us to create our new game review, accuracy, and rating systems. These all have a big impact on how the Royal Game of Ur is played!
Here's the story of how we figured out how to solve this ancient board game, and what it means for you as a Royal Game of Ur player.

It's a pretty big deal!
For the last four millennia the optimal strategy for the Royal Game of Ur has been a mystery. Now, for the rest of time, it will be solved. How cool is that!!
Let me try to explain why this matters. In the Royal Game of Ur, you throw dice to see how far you can move. These dice bring a lot of fun to the game, but they also make it hard to objectively evaluate strategy. You could never really tell whether you got lucky, or whether you played really skillfully. Now you can!
Solving the game has brought your skill in the Royal Game of Ur out of obscurity and into sharp focus. This is a big deal for a game where luck plays a significant role in who wins each game, especially at higher levels. This is why solving the Royal Game of Ur fundamentally changes how strong players approach the game.
And it all started from a group of people becoming interested in an obscure ancient board game, and working on it together towards an end that we didn't even know would ever come.
Watch flawless play
Before we go any further, here's a little live demo. Below, two bots engage in a flawless duel - perfect play! I find it mesmerising. How often do you get to watch something and know it is mathematically perfect?
The breakthrough 🎯
We spent years hiking through the woods to improve our AI for the game. And then we realised there was a highway slightly to our left...
Before solving the game, our bots were simple and search-based. They would simulate millions of moves to figure out the one move they should make. This approach was unsophisticated, and so it took years of fine-tuning to get it to work well.
Throughout the years, we would always give the same codename to our latest and best bot: the Panda!
We optimised the Panda, updated how it searched, and improved its heuristics. We made a lot of progress! Before solving the game, the Panda was playing with an average accuracy of 87%, whilst also running on most of our player's phones. That's only a few percentage points shy of Arthur, one of the strongest Royal Game of Ur players in the world.
However, just as we thought we might narrowly pass Arthur, a new researcher, Jeroen, joined our Discord. Soon after, we had not only beaten Arthur's skill - we had smashed it!
We set the Panda on a completely new training regimen. And only a couple of weeks later, we had done something we didn't even realise was possible. We had calculated the statistically best move to make from every possible position in the game. 100% accuracy. Perfect play.
We had solved the Royal Game of Ur!
That was a bit of a shock to the system.
The Panda now plays flawlessly
The Panda now ruthlessly cares about just one thing: winning. It does not care about trivial details such as losing pieces, scoring, or capturing. No, it only cares about how each and every move it makes affects its final chance of winning the game.
If sacrificing a piece gave the Panda a 0.01% improved chance of winning, the Panda would play that move. In this way, the Panda plays the Royal Game of Ur flawlessly. There is no strategy that you can use to outplay the Panda. You can only hope to match its skill!
How does it know what is best? It's pretty simple actually. We have calculated your chance of victory from every single position in the game. Once you know that, you can just pick the move that leads to your highest chance of winning. Easy!

The game has changed 👑
Solving the game has unlocked strategic depth for the Royal Game of Ur. The dice made it hard to determine whether you won or lost due to strategy or luck. No longer.
Using the solved game, we can now perceive the full strategic depth in every move, every decision, and every careful placement of your pieces. You may still be playing the same game that people played four millenia ago. But now we can appreciate the true quality of your play. The dice no longer hide that from us.
This has created a whole new game within a game - a sophisticated and challenging puzzle that asks not merely "Can you win?" but rather "Can you find the perfect answer to each position?"
Many of our best players now aim to play the best possible game, not just to win. This is a fundamental shift in the game. If you lost, but you played with an accuracy over 80%, you still played an outstanding game. This raises the ceiling on how good players can get.
Now our job is to build the tools to help our players reach these new heights!

You can defeat perfection! 🐼
You can now play the perfect player right here on RoyalUr by selecting the Panda as your opponent. The Panda is a ruthless opponent, but with some skill and a lot of luck, it is possible to win! If you'd like to see if you can beat the perfect AI yourself, you can try playing the Panda here.
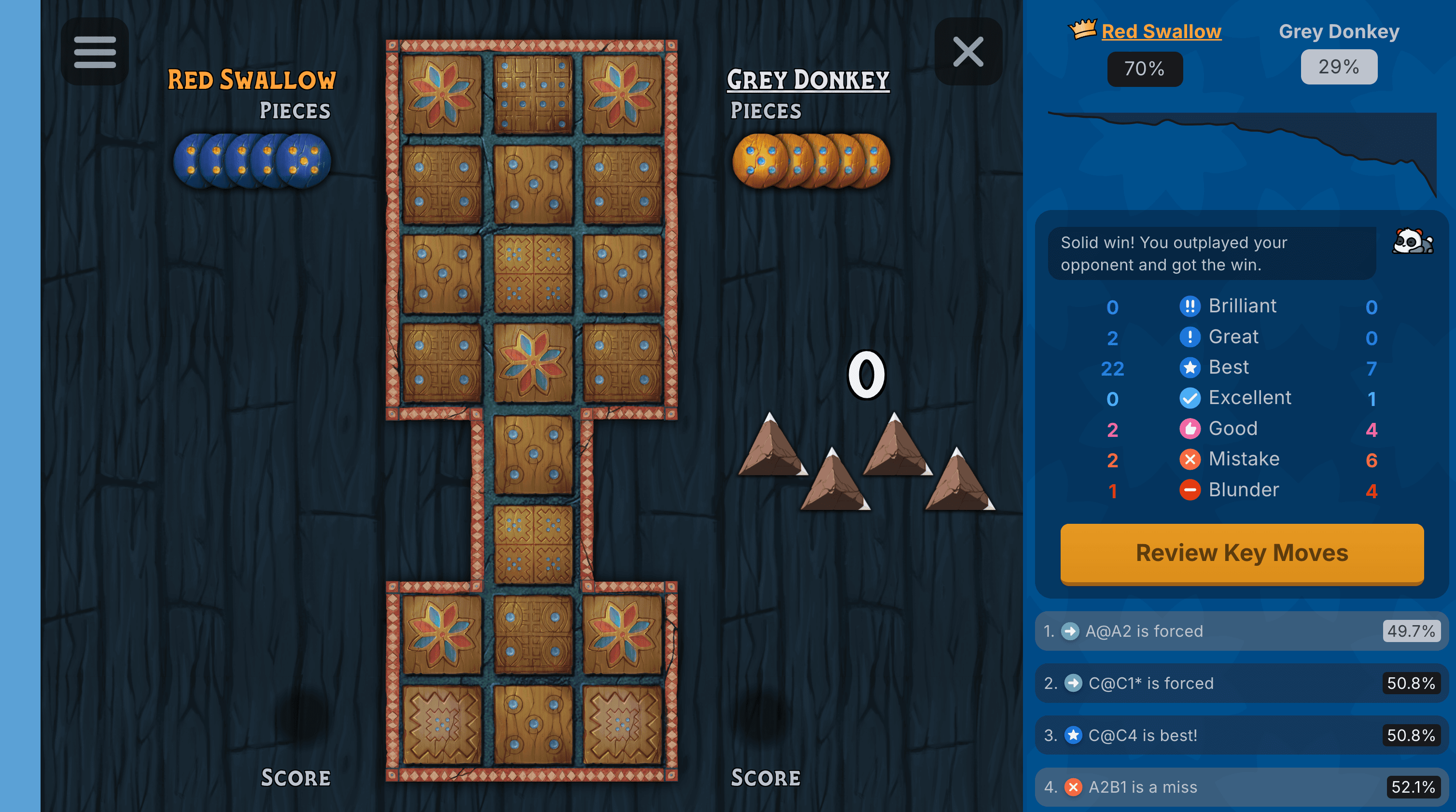
Solving the game has also allowed us to release another major feature that we've been working on for a very long time: game review! Game review employs the perfect player to analyse your moves, highlight your best moments, and suggest improvements.
In other words, we've created a computer teacher to help you learn the game. I am truly proud of it, and we will continue working to make it the best teacher it can be. If you'd like to give it a try, you can access an example game review here.
This was not a solo effort 🤝
Here I will give a vastly shortened list of the people who contributed to solving the game. There are also many more people who contributed through the research discussions we have held since 2021!
- Jeroen Olieslagers. The problem-solving master. Jeroen was the first to prove the feasibility of solving the Royal Game of Ur using value iteration by solving the 2-piece game. I wouldn't be writing this article if it weren't for Jeroen joining our Discord a year ago!
- Raphaël Côté. The man that gets stuff done. Raph is the reason that you can load the perfect-play maps in Python. He is also the person that brings us all together to research the Royal Game of Ur!
- Mr. Carrot. The catalyst for critical thinking. Mr. Carrot came up with the idea that the game is symmetrical, which halved the memory requirements of our models.
- Padraig Lamont. I created this website, RoyalUr.net, back in 2017, and our Discord community in 2021. This is also me writing this, hello!
Join us! 🚀
Solving the Royal Game of Ur isn't an endpoint - it's a launchpad. As this ancient game moves into the modern age, people are creating beautiful boards, organising enthralling tournaments, and fostering the most welcoming communities you'll ever see. The modern era of the Royal Game of Ur is quickly marching into reality.
Join us! If you are interested in history, probability, AI, or if you enjoy a fun casual game with friends, you will probably like the Royal Game of Ur. Join our community, try your hand against our perfect AI, and who knows? You might just defeat perfection.
Head to our homepage to start your journey with the Royal Game of Ur. I look forward to playing you some time :D
Thanks :)
~ Paddy L.